Memahami Arsitektur Medallion dalam Data Engineering

Dalam platform data modern, khususnya dengan berkembangnya konsep data lakehouse (seperti Databricks), Arsitektur Medallion telah menjadi standar untuk membangun pipeline data. Ini adalah pendekatan berlapis yang memastikan aliran data berlangsung secara terkontrol, andal, dan siap untuk kebutuhan bisnis.
Mari kita uraikan layer demi layer, serta satu ekstensi tambahan: Rekonsiliasi.
Layer Bronze: Data Mentah
Lapisan Bronze adalah area awal untuk data mentah yang belum diproses.
Data dimasukkan langsung dari sistem sumber (database, API, file, aliran IoT, dll.).
Tidak ada pembersihan atau transformasi yang dilakukan di sini — data disimpan apa adanya demi keterlacakan.
Anggap ini sebagai sistem pencatatan utama Anda.
Contoh: Dump CSV dari transaksi, log dari aplikasi, atau data sensor yang disimpan dalam format Delta/Parquet.
Catatan Lanjutan: Dalam beberapa implementasi, digunakan ingestion berbasis metadata agar skema, partisi, dan lineage otomatis tercatat pada tahap ini.
Detail Mendalam: Perusahaan besar sering menggunakan CDC (Change Data Capture) atau ingestion streaming (melalui Kafka, Kinesis, atau Event Hubs) untuk memastikan lapisan Bronze mencerminkan perubahan hampir real-time dari sistem operasional.
Layer Silver: Data yang Dibersihkan & Diperkaya
Lapisan Silver mengambil data Bronze dan menerapkan pembersihan, normalisasi, dan standarisasi.
Duplikasi dihapus, data buruk difilter, dan kolom dikonversi ke format yang benar.
Ini juga tempat penggabungan dengan data referensi/master dilakukan.
Silver memastikan konsumen downstream bekerja dengan data yang andal, akurat, dan terstruktur.
Contoh: Transaksi yang sudah dibersihkan dengan timestamp yang benar, format mata uang konsisten, dan kode produk yang dipetakan.
Catatan Lanjutan: Pada tahap ini, dimensi perubahan lambat (SCD) atau surrogate key sering diperkenalkan untuk konsistensi antar dataset.
Detail Mendalam: Dalam implementasi modern, Silver sering memperkenalkan kontrak kualitas data — aturan eksplisit seperti pemeriksaan null, validasi ambang batas, deteksi perubahan skema, dan validasi integritas referensial. Beberapa proyek juga menambahkan lapisan Silver+ karena tabel yang sama digunakan dengan filter berbeda oleh beberapa lapisan Gold.
Layer Gold: Data Siap Bisnis
Lapisan Gold disesuaikan untuk use case bisnis.
Data di sini diagregasi, dimodelkan, dan dioptimalkan untuk analitik, dashboard, dan ML.
Lapisan ini adalah tempat pembuatan KPI, metrik, dan dataset yang sudah dikurasi.
Secara sederhana, ini adalah single source of truth untuk pelaporan.
Contoh: Ringkasan penjualan harian per wilayah, dataset customer 360, fitur prediksi churn.
Catatan Lanjutan: Data pada lapisan ini sering dipublikasikan sebagai model semantik atau feature store untuk melayani alat BI dan pipeline ML secara real-time.
Detail Mendalam: Banyak organisasi menanamkan kebijakan tata kelola dan keamanan di sini: kontrol akses berbasis peran, keamanan tingkat baris, dan masking PII. Ini memastikan dataset yang siap bisnis mematuhi regulasi seperti GDPR, HIPAA, atau aturan keuangan.
Layer Rekonsiliasi (Ekstensi)
Sementara Bronze-Silver-Gold mencakup ingestion, pembersihan, dan konsumsi, banyak organisasi menghadapi celah: memvalidasi apakah data yang dihasilkan sesuai dengan sumber.
Di sinilah lapisan Rekonsiliasi diperlukan.
Langkah ini memverifikasi jumlah, total, dan metrik kunci antara data sumber dan data yang sudah diproses.
Ini memastikan tidak ada record yang hilang, duplikat, atau korup.
Laporan rekonsiliasi sering dibagikan dengan auditor atau pengguna bisnis untuk membangun kepercayaan.
Ini sangat penting di industri jasa keuangan, yang penuh regulasi, dan analitik yang bersifat kritis.
Contoh: Jika sumber menunjukkan 1.000 transaksi dengan total $1 juta, pipeline Silver/Gold harus menampilkan hal yang sama, atau menjelaskan perbedaannya.
Mengapa Semua ini Penting?
- Bronze menjaga kebenaran dari data mentah.
- Silver memastikan keandalan data yang bersih.
- Gold memberikan business insight.
- Rekonsiliasi menambah kepercayaan.
Semua lapisan ini menciptakan pipeline data yang kuat, dapat diaudit, dan skalabel yang dapat melayani analitik, ML, dan kebutuhan kepatuhan tanpa kompromi.
Jika Anda membangun pipeline di Databricks, Spark, atau arsitektur lakehouse apa pun, mengadopsi Medallion + Rekonsiliasi akan membuat platform data Anda tepercaya dan future-proof.
Contoh Real-time: E-commerce Orders (Streaming)
Mari kita lihat gambaran nyata end-to-end pipeline yang berjalan near real-time (di bawah satu menit) dan menggunakan Arsitektur Medallion + Rekonsiliasi.
Sumber Data:
- OLTP: orders, order_items, payments di PostgreSQL (CDC via Debezium).
- Aplikasi/Event: cart_viewed, checkout_started dikirim ke Kafka.
- Data referensi: products, geo, exchange_rates (snapshot per jam).
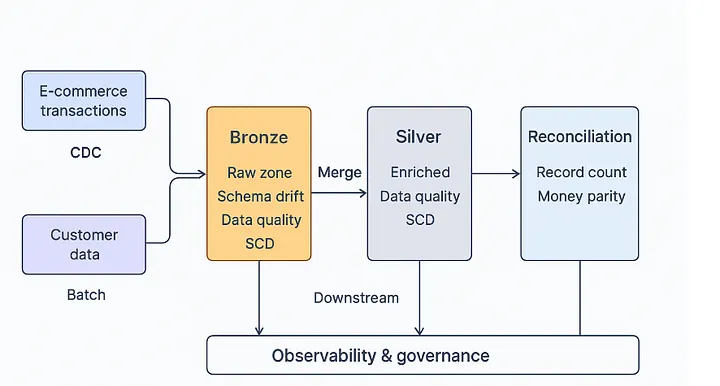
Bronze (landing raw):
- Ingestion: Debezium → Kafka topic (satu per tabel) → Auto-loader (Databricks) menulis tabel Delta yang dipartisi berdasarkan ingest_date.
- Tabel: bronze.orders_raw, bronze.order_items_raw, bronze.payments_raw, bronze.events_raw.
- Garansi: Append-only, tanpa logika bisnis. Simpan semua CDC.
- Penanganan duplikasi (ditunda): Jangan deduplikasi dulu; simpan apa adanya.
Silver (clean, conform, enrich):
- Tujuan: Upsert idempoten, penerapan skema, SCD, integritas referensial.
- Deduplikasi berdasarkan business key order_id.
- Normalisasi nilai uang ke USD dengan exchange_rates.
- Gabungkan produk & geo, validasi enum (status), ubah tipe data.
- Bangun dimensi SCD2: dim_customer, dim_product.
- Tabel: silver.orders, silver.order_items, silver.payments, silver.dim_customer.
Gold (business-ready data mart):
- Star schemas: fact_orders terhubung dengan dim_date, dim_customer, dim_product, dim_region.
- KPI: GMV, AOV, conversion rate, cancellation rate, payment success %, on-time shipment %.
- Serving: Power BI/Looker di atas Delta; fitur ML (misalnya orders_last_7d, avg_basket_value_30d) dibuat untuk model churn.
Rekonsiliasi (trust & audit):
- Jumlah record per hari dan per tabel sumber (dengan toleransi untuk penghapusan/pendatang terlambat).
- Total moneter: jumlah payments.amount_usd vs jumlah order_items.net_amount_usd ± pembulatan/biaya.
